Hi,
I'm very new to OpenCL and JOCL.
I'm using a dual gpu HD7990 on win7 64, Catalyst 14.12 and having some problems getting reliable execution across both gpus concurrently. If I run the JOCLMultiDeviceSample I can see it enqueue work to both gpus however the work fully executes on one gpu before the work on the second gpu commences.
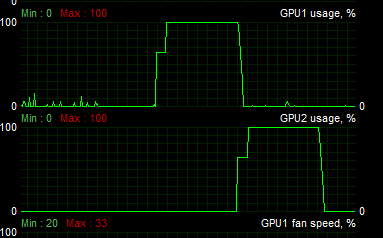
Note that since the sample runs over all devices I can also see the CPU work occurring concurrently to the GPU work.
My own launcher and kernels behave the same way - If I schedule the same work to both gpus and use clWaitForEvents(...) to wait for both jobs to complete they execute serially taking 2x the time of one job. When I run a thread per device (with separate context) AND force the work on the first core to be scheduled before that on the second core then both jobs execute concurrently and both jobs complete in the same time as a single job on one gpu.
Any pointers as to whether this is an issue with the dual card / driver or a synchronisation problem in the JOCL wrapper?
Thanks, Joe

